The Black Box Has a Group Chat
Mechanistic interpretability, AI safety, and my first blog
By Shashwat Raj · Issue No. 001
This is my first blog, so naturally I decided to start with something light and casual: the internal mechanics of large language models, AI safety, privacy leakage, and the tiny existential question of whether the systems we are building actually understand what they are doing.
Very normal. Very beginner-friendly. Extremely "I had one coffee too many during exam season."
I am writing this as a math major at ASU, which means half my brain is usually occupied by problem sets, proofs, exams, and the deeply humbling experience of staring at a theorem and realizing the theorem is staring back. The other half, for some reason, has recently been stuck on mechanistic interpretability.
Why this keeps pulling me back
Mechanistic interpretability is basically the field of asking: What is actually happening inside the model?
Not just what the AI says. Not just whether the answer looks good. But what internal features, circuits, attention heads, and mathematical gremlins caused the answer to appear in the first place.
User: "Can you help me with this?"
Model: "Absolutely."
User: "Why did you answer that way?"
Model: "Here is a very confident explanation."
Mechanistic interpretability researchers: "Okay but what actually happened inside your little neuron casino?"
That is the part I find fascinating.
AI models are often called black boxes, and that phrase gets thrown around so much that it has almost become background noise. But the problem is real. These systems are increasingly being used in medicine, law, education, software, finance, and every other domain where mistakes are not just funny screenshots for Twitter. If a model gives a good answer, that is nice. But if we cannot understand why it gave that answer, we are still basically trusting vibes.
And vibes are not a safety framework.
They are barely a group project strategy.
Safety needs more than vibes
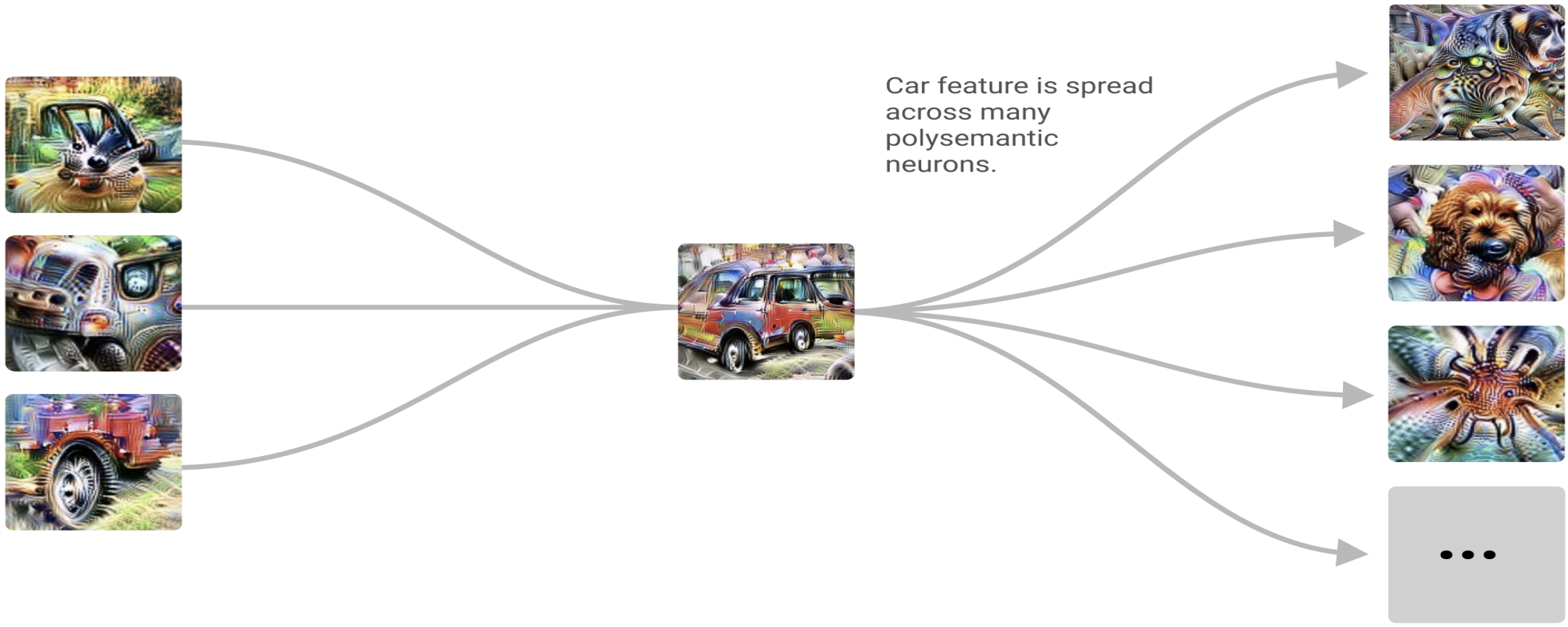
Researchers at Anthropic and in the broader transformer-circuits community have shown that models appear to contain internal "features" and "circuits" associated with concepts and behaviors. Anthropic's work on Claude Sonnet, for example, identified millions of interpretable features inside a production-grade language model, while earlier transformer-circuits work studied mechanisms like induction heads, which help models recognize and continue patterns from context.3, 5
To make this less mystical, an LLM like GPT, Claude, or MiniMax is basically a giant learned function that turns text into tokens, tokens into vectors, and vectors into a long chain of internal transformations. GPT-4, for example, is described by OpenAI as a Transformer-style model trained to predict the next token in a document; so at the lowest level, the model is not "thinking in English" first, it is updating high-dimensional numerical representations that make the next word, symbol, or code fragment more or less likely.1, 2 Inside those layers, attention heads move information between positions in the context, MLP layers transform and store abstract features, and residual streams carry information forward through the network. This is why mechanistic interpretability cares about things like "features," "circuits," and "induction heads": an induction head, for example, is a specific kind of attention behavior that can help a model recognize a repeated pattern and continue it, like seeing "A B ... A" and predicting "B."5 Claude is especially relevant here because Anthropic has shown that millions of human-interpretable features can be identified inside Claude 3 Sonnet, including features connected to concepts, behaviors, and safety-relevant topics.3 MiniMax makes the picture even more interesting because MiniMax-Text-01 uses a hybrid architecture combining Lightning Attention, Softmax Attention, and Mixture-of-Experts routing, with 456 billion total parameters and 45.9 billion activated per token.7 So when a model gives a safe-looking answer, there is a lot hidden under the rug: which attention heads routed information, which features activated, whether the model used a stable safety-related circuit, whether sensitive information survived in an internal representation, and whether the final answer reflects faithful reasoning or just a polished post-hoc explanation. Mechanistic interpretability is the attempt to reverse-engineer that middle zone between prompt and output. It asks not just "what did the model say?" but "what internal mechanism made it say that?" That is why it matters for AI safety: if GPT, Claude, MiniMax, and the next wave of frontier models are going to sit inside real workflows, we need to understand the machinery that converts prompts into behavior.
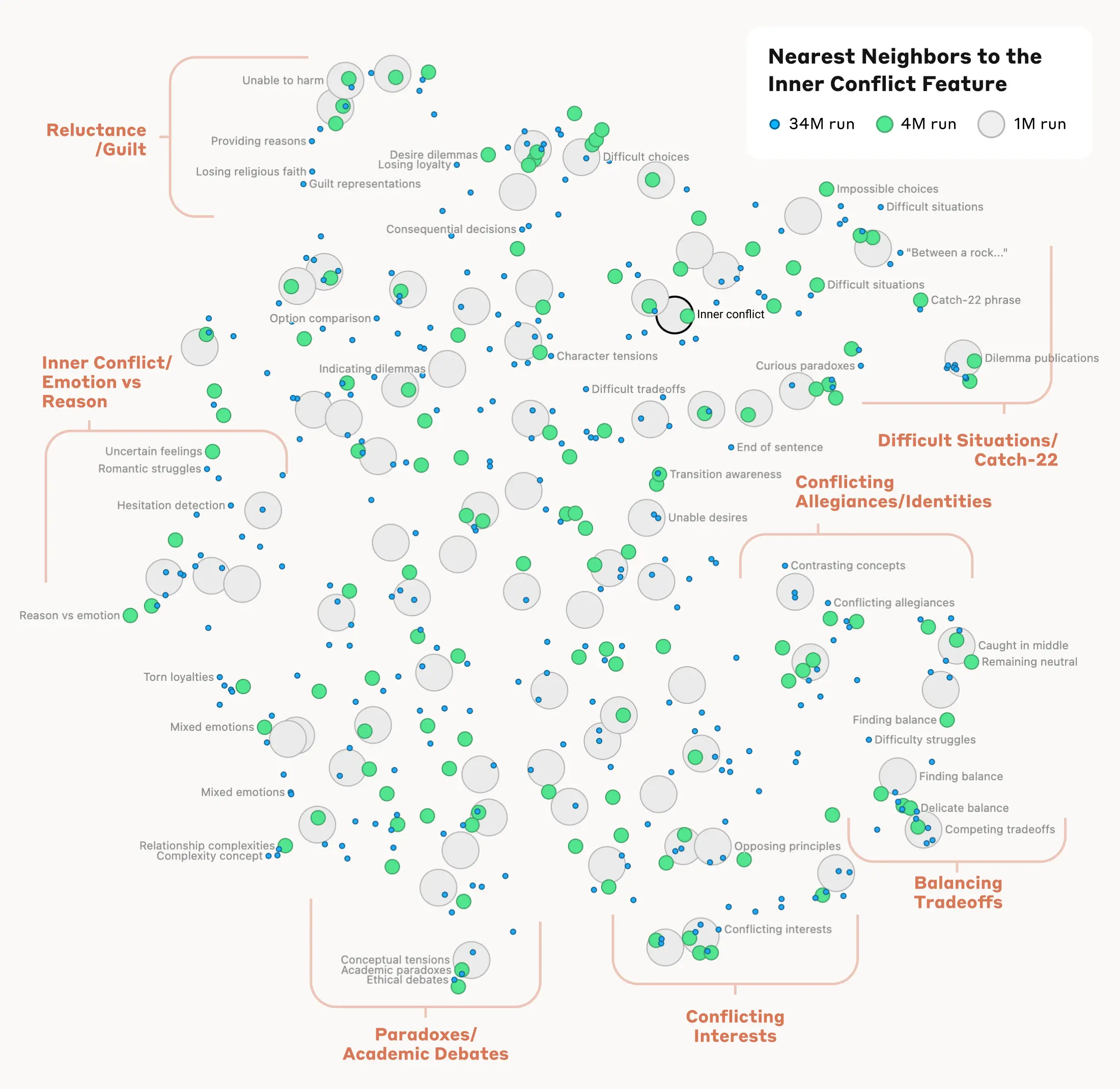
That is genuinely cool because it suggests that models are not just mystical autocomplete fog machines. There are internal structures we can begin to map.
But it is also terrifyingly funny because the map is not clean.
One neuron does not necessarily mean one concept. A neuron can be involved in multiple things, and one concept can be spread across many neurons. This is where words like polysemanticity and superposition enter the chat. In normal English, it means the model is packing concepts into its internal space like an ASU student trying to fit clothes, books, snacks, laundry, and emotional instability into one backpack before class.6
This is where AI safety gets interesting.
A model refusing a harmful request is not enough. I want to know why it refused.
Did it understand the safety boundary?
Or did it just see danger-shaped words and press the "polite refusal" button?
Those are very different. One is closer to actual safety. The other is a bouncer checking outfits instead of IDs.
That difference matters because AI systems can look safe on the outside while being fragile on the inside. They can pass a test because the prompt looked familiar. They can explain themselves in a way that sounds reasonable but does not reflect what actually happened internally. Anthropic's circuit-tracing work has already shown that the mechanism behind a model's behavior is not always obvious from the polished explanation it gives you afterward.4
This is why I keep coming back to the same thought:
Behavior is not enough. We need receipts from the black box.

HackPrinceton made it concrete
This became more real to me while working on Asclepius at HackPrinceton Spring 2026. I will not go too deep into the technicals here, but the experience made the safety question feel a lot less abstract: sometimes the danger is not that a model says something evil. Sometimes the danger is that the system is useful in exactly the wrong way. And people are usually much more willing to optimize for the faster, easier, working process than to sit with the ethical implications.
Also, small personal side quest and unexpectedly great news: Asclepius ended up winning Best Overall Hack at HackPrinceton Spring '26, along with recognition in the d_model AI Research and Alignment track and the Regeneron clinical trials track. That was unreal. Winning was already a "wait, did that actually happen?" moment, but winning an entire PS5 for it made the whole thing feel even more ridiculous in the best way. Yes, we did not sleep for an entire weekend and somehow our half-dead team of four walked away with four PlayStations. You can check out Asclepius on Devpost.
I also met really cool people like Mr. Andrew Gordon and Dr. Henry Wei, both industry professionals in this space, and those conversations shifted how I think about safety, especially my convo with Dr. Wei.
Before that, I thought of safety mostly as guardrails. You build the model, test it, patch the obvious bad behavior, and then hope the thing behaves.
Now I think that is only one layer.
Real safety has to ask deeper questions:
- What information is flowing through the system?
- What internal mechanism caused the output?
- What happens when the input changes slightly?
- What does the model know, infer, memorize, hide, or reconstruct?
- What breaks when the system is put under pressure?

What I want from this field
That is where mechanistic interpretability feels less like an academic niche and more like a necessary microscope.
As a math person, I think part of the appeal is that mechanistic interpretability feels like trying to prove something about a system instead of just observing it. In math, you do not just say, "This seems true because it worked on three examples and the graph looked friendly." You need the argument. You need the structure. You need the reason.
AI safety needs that same energy.
Not just: "The model gave a safe answer."
But: "Here is the internal mechanism that produced the safe behavior, and here is why we believe it will generalize."
That is a much harder standard. But it is also the standard that matters if AI systems are going to keep moving into high-stakes environments.
The funny part is that I am writing all this while juggling exams, assignments, and the usual student calendar that looks like someone rage-clicked "add deadline" fifteen times. There is something very on-brand about studying math during the day, then spending late nights reading about model internals and thinking, "What if the neurons are doing side quests?"
But that is also why this topic has been sticking with me.
Mechanistic interpretability feels like curiosity with consequences.
It is not curiosity for the sake of sounding smart. It is curiosity because we are building systems that may soon become too important to leave unexplained.
I do not think interpretability magically solves AI safety. It will not. The field is still early, messy, expensive, and sometimes looks like a conspiracy board made by someone who had three cold brews and a deadline.
But I do think it gives us one of the best chances to move from:
"Trust us, the model is aligned."
to:
"Here is what we found inside the model, here is how it caused the behavior, and here is what still scares us."
That honesty matters.
Because if the future of AI depends on systems we cannot inspect, then we are basically asking the black box to pinky-promise that it will behave.
And respectfully, I would prefer more than a pinky promise from a stochastic parrot with great branding and a suspiciously polished apology template.
So that is where I am starting with this blog: somewhere between ASU exam season, math-brain overthinking, hackathon adrenaline, and a genuine belief that understanding models is one of the most important steps toward making them safer.
Thanks for reading till the end, especially since this is my first blog. I am still figuring out the voice, the structure, and how much technical chaos is socially acceptable in a personal post. But if there is one idea I want to leave you with, it is this:
The output is only the screenshot.
The mechanism is the story.
P.S. If this was boring, answer one question for me: what brand is your microwave?
References
- OpenAI, "GPT-4."
- Anthropic, "Mapping the Mind of a Large Language Model."
- Anthropic, "Tracing the thoughts of a large language model."
- Olsson et al., "In-context Learning and Induction Heads."
- Elhage et al., "Toy Models of Superposition."
- MiniMax, "MiniMax-01: Scaling Foundation Models with Lightning Attention."
Next issue
More personal, more technical, probably still slightly unhinged.
If you want the next post without visiting this web page each time, subscribe and I'll send it directly.
Subscribe to Newsletter