Is Quantum Computing also awaiting a Transformers Moment?
How Transformers became modern AI's default architecture, and why quantum is still looking for its own scalable abstraction/convergence
Why did one architecture become the common grammar of foundation models in the first place?
And once that architecture scaled, what did it reveal about the limits of the physical world underneath AI? That is the trail that kept leading me from Transformers to power demand, from GPUs to energy systems, and from there to quantum computing. Not because quantum is some clean replacement for AI, but because once the bottlenecks stop being purely algorithmic, the conversation gets dragged into physics whether we like it or not.
Why Transformers walked in and took over the room
AI used to feel like a crowded engineering party.
CNNs were standing near the vision table with quiet confidence. RNNs and LSTMs were trying very hard to remember the order of every conversation. Decision trees were in the corner solving business problems without making a big deal out of it. GANs were showing everyone suspiciously realistic faces. Reinforcement learning had arrived wearing sunglasses indoors and was teaching a robot to fall over with purpose.
Then Transformers walked in.
Not politely. Not quietly. More like someone joining a group project two hours before the deadline and somehow carrying the final submission.
Transformers did not win because every other model became useless.
They won because they arrived at the exact intersection of flexibility, parallelism, and scale.
That is the part worth studying.
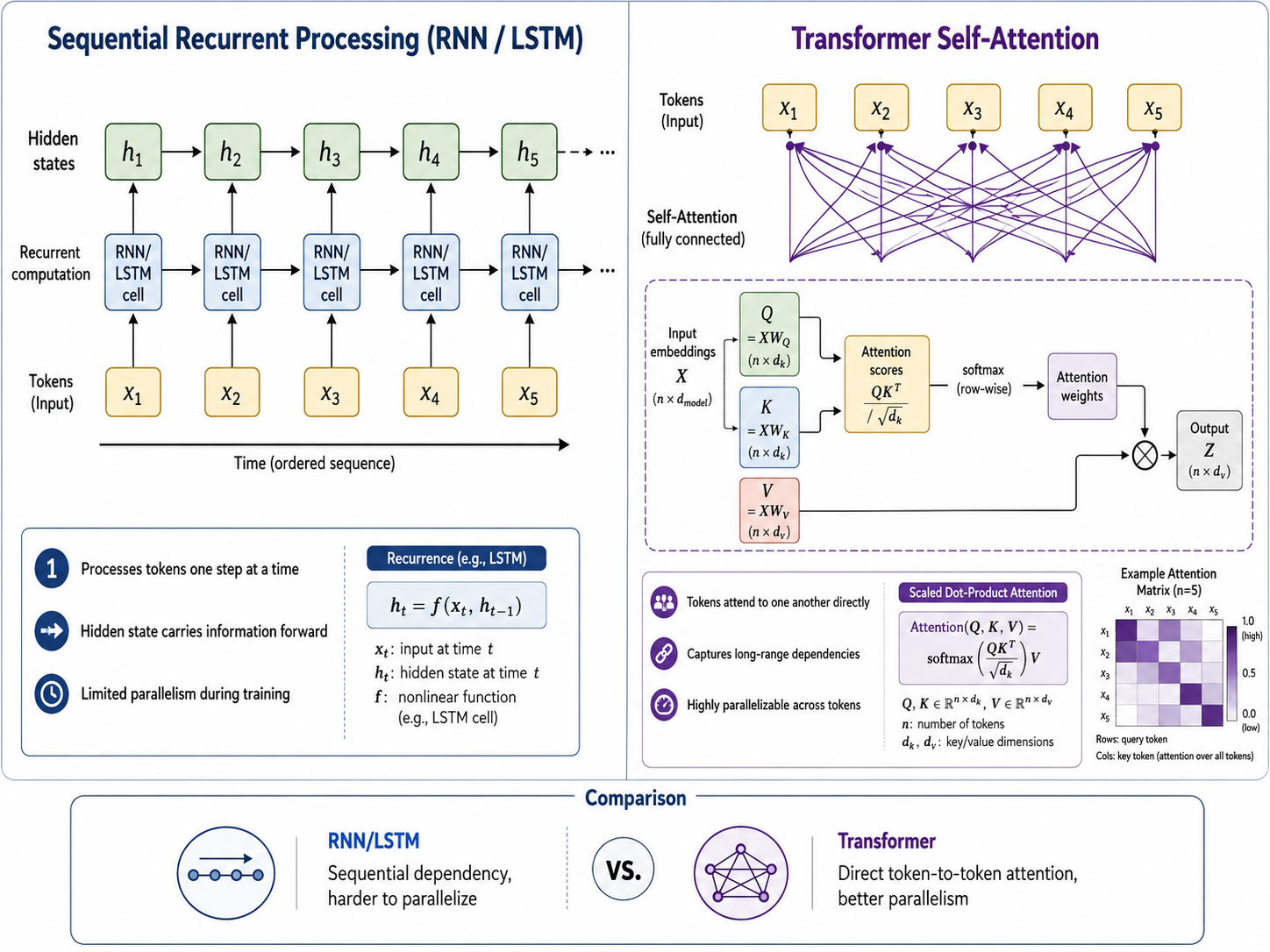
The original 2017 paper, Attention Is All You Need, proposed a sequence-transduction architecture based entirely on attention, removing recurrence and convolutions from the core model while reporting strong translation performance with significantly more parallelizable training.1 That last part mattered more than the joke-friendly title. Parallelism was not just a nice engineering detail. It was the feature that aligned the model with the hardware era.

Before Transformers, recurrent models processed sequences more like someone reading a novel one page at a time. Useful, sometimes elegant, but stubbornly sequential. Transformers changed that rhythm. Self-attention let tokens relate directly to other tokens in the sequence. A word could attend to another word. A code token could attend to another code token. An image patch could attend to another image patch. The model was not simply walking through a sequence anymore. It was building a relationship map across it.
That makes for a better fit with accelerators. GPUs and TPUs reward workloads that can be parallelized. Transformers were not just conceptually expressive. They were computationally convenient.
The architecture became a language
Then came portability.
Language became tokens. Code became tokens. Images became patch tokens. Audio could be represented as sequences. Even some biological data could be treated as sequence-like under the right framing. Once many domains could be translated into token-ish representations, the same broad architectural pattern started traveling unusually well.
BERT showed that Transformer-based pretraining on unlabeled text could be adapted across a wide range of NLP tasks with minimal task-specific architectural surgery.2 GPT-3 showed that scaling autoregressive Transformer language models unlocked broader few-shot performance across many tasks.3 Vision Transformer pushed the same basic story into image recognition by splitting images into patches and treating them like sequence elements.4
That is when Transformers stopped feeling like one clever neural-network block and started feeling like a general-purpose interface for large-scale learning.
A little funny, honestly. The architecture that made "attention" famous ended up getting most of the attention.
Of course, none of this means the rest of machine learning packed up and left. That would be too clean, and machine learning does not believe in clean narratives.
Tree-based models still perform extremely well on many tabular problems. A large benchmark comparing 19 algorithms across 176 datasets found that the "neural nets versus boosted trees" debate is often overstated, and that small differences in tuning can matter more than switching model families entirely.5 Diffusion models became one of the defining paradigms in image generation, with research showing they can outperform GANs on image synthesis benchmarks.6 Even sequence modeling is no longer a one-team league; Mamba was explicitly proposed as a selective state-space alternative to address Transformer inefficiencies on long sequences, while noting how thoroughly foundation models had already converged on Transformer-style design.7
So the honest picture is not monoculture.
It is more like a dominant dialect.
Modern AI still speaks many architectural languages, but the foundation-model world increasingly sounds fluent in Transformer.
Scaling turns into an infrastructure story
And that fluency came with a cost.
The same design pattern that made modern AI feel general also made it resource-hungry. Hungry for chips. Hungry for memory bandwidth. Hungry for power. Hungry for cooling. Hungry for data centers that make local grids wonder whether they accidentally signed up for a stress test.
This is where the story stops being only about algorithms and becomes a story about infrastructure. The bottleneck is no longer just whether we can design a smarter model. It is whether we can power it, cool it, manufacture enough accelerators for it, connect enough data centers for it, and do all of that without turning every utility planner into the unwilling protagonist of an industrial panic attack.
The model is digital.
The bill is physical.
The International Energy Agency projects that global data-center electricity consumption could more than double to around 945 TWh by 2030, with AI as a major driver of that growth.8 RAND's 2025 analysis sharpens the point further: global AI data-center power demand could reach 68 GW by 2027, and individual AI training runs could require up to 1 GW in a single location by 2028 under exponential-growth assumptions.9
So yes, Transformers helped AI scale.
But scaling has receipts.
Where quantum actually enters the conversation
This is where quantum computing starts to matter more naturally.
Not as "the next architecture after Transformers." That is too direct and probably wrong. Quantum becomes interesting because the AI era is exposing bottlenecks that are not purely software bottlenecks anymore. Some are compute bottlenecks. Some are optimization bottlenecks. Some are chemistry and materials bottlenecks hiding under the infrastructure layer.
Better chips require better materials. Better batteries require better chemistry. Better cooling systems require better thermal engineering. Better grids require better optimization. Better AI infrastructure may depend not only on better neural networks, but on better physics.
Quantum computing, in its most credible long-term form, is a bet that some problems rooted in quantum physics may be better handled by machines that use quantum physics directly. The National Academies report emphasizes both the original motivation for quantum computing and the more realistic framing that quantum machines are unlikely to replace classical computers outright. They are better thought of as specialized accelerators or co-processors for certain problem classes.10
That framing matters because it keeps the argument honest. Quantum computing will probably not make tomorrow's chatbot cheap. It is not going to walk into a hyperscale data center, pat the GPU cluster on the back, and cut the electricity bill in half.
The stronger argument is more indirect and, because of that, more believable: quantum computing may eventually help with the scientific and optimization problems that surround the AI economy. Materials discovery. Chemistry simulation. Semiconductor design. Battery chemistry. Thermal management. Energy systems. Maybe even certain machine-learning workflows, though that part remains much more speculative.
In other words, quantum is not interesting because it replaces AI.
Quantum is interesting because some of AI's next bottlenecks may not be solvable by AI alone.
Quantum is still searching for its abstraction layer
This is also exactly where the hype needs discipline.
Quantum computers are not magic GPU dust. Current and near-term machines are noisy, difficult to control, and limited by error rates. The National Academies report points to noisy gates, limited measurement, difficulty loading large amounts of classical data efficiently, and the central challenge of error correction.10 That data-loading problem is especially important for AI. Modern AI runs on enormous classical datasets. If moving classical data into quantum states is itself inefficient, then quantum computing does not automatically become a shortcut for training large neural networks. The bottleneck just changes clothes and becomes even less friendly.
John Preskill's NISQ framing still feels useful here. Noisy intermediate-scale quantum devices may help explore many-body quantum physics and possibly some other applications, but a 100-qubit machine is not instantly world-changing just because it sounds futuristic.11
One of the most credible near-term bridges may actually run from AI to quantum, not quantum to AI. AI is already being studied as a tool for developing and operating quantum systems: designing hardware, tuning devices, optimizing control, improving error correction, and managing complicated experimental setups. A 2025 Nature Communications review explicitly centers this "AI for quantum" direction and separates it from the more speculative long-term idea of "quantum for AI."12
That relationship matters. AI may help build better quantum systems. Quantum systems may eventually help solve scientific and infrastructure problems that support the next generation of AI. The relationship is less "replacement" and more "feedback loop."
The long-term prize is fault-tolerant quantum computing, where many imperfect physical qubits are combined into more reliable logical qubits. Recent work from Google Quantum AI reported below-threshold surface-code memories on its Willow superconducting processor, meaning logical error rates were suppressed as code distance increased. That is an important step for scalable error correction.13
But it is still a milestone on the road, not the destination.
This is where the comparison to Transformers gets interesting again.
AI found a powerful abstraction: tokens plus attention plus scale.
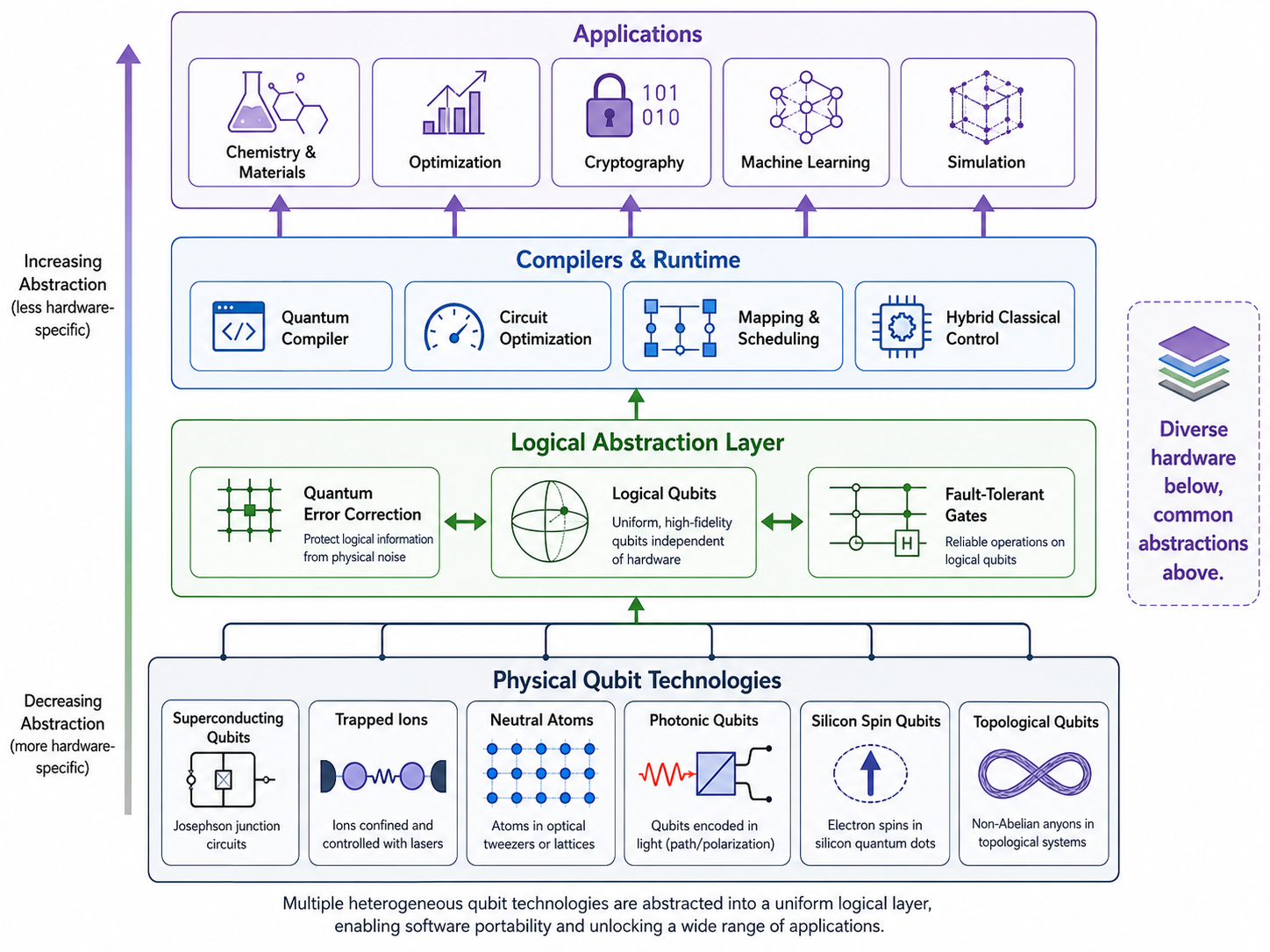
Quantum computing is still searching for the abstraction layer that lets it scale.
Maybe that layer is hardware. Maybe superconducting qubits win. Maybe trapped ions win. Maybe neutral atoms scale better. Maybe photonics becomes the surprise platform. Maybe silicon spin qubits benefit from semiconductor manufacturing. Maybe the field has not yet identified the eventual winner.
Or maybe convergence does not happen at the physical layer at all.
Maybe the real "Transformer moment" for quantum is a common logical layer: fault-tolerant, gate-based quantum computing where developers work with logical qubits and circuits without caring too much about the underlying hardware. In AI, the convergence happened around a software architecture. In quantum, it may happen around error correction, logical qubits, compilers, programming models, and hybrid quantum-classical workflows.
That would look a lot more like cloud computing than like model architecture fandom. Most people writing Python are not thinking about transistor physics. They assume the abstraction works, and then they blame the API when it doesn't, as tradition demands.
But another possibility is more plural and maybe more realistic: quantum computing may not converge cleanly. Different problem classes may favor different machines. Chemistry, materials simulation, cryptography, optimization, and many-body physics may not all want the same architecture. The physical world is stubborn. It does not always allow the kind of elegant abstraction software people keep trying to bully it into.
AI could flatten many things into tokens.
Quantum still has to negotiate with matter.
The question I keep returning to
That, to me, is the real lesson from Transformers. Not that every field eventually finds one architecture and everyone else goes home. The lesson is more specific: a field starts to feel unified when one approach becomes technically strong, hardware-compatible, economically scalable, and easy for the ecosystem to build around.
Transformers did that for foundation models.
Quantum computing has not found that shape yet.
Maybe it will. Maybe the winning abstraction will be logical qubits rather than physical qubits. Maybe the future is hybrid quantum-classical computing. Maybe it is a messy ecosystem of specialized quantum machines, each optimized for a different problem class.
Either way, the question is too good to ignore.
The Transformer became the architecture of attention because it gave AI a scalable way to model relationships. But once AI scaled, it slammed into the physical world: power, chips, cooling, materials, grids, and energy. Quantum computing matters not because it is the next shiny object after AI, but because some of AI's hardest future bottlenecks may live in places where physics itself becomes the problem.
And if physics is the problem, maybe physics also becomes part of the computer.
This is probably why the topic keeps pulling me back. As a math major, I like fields when they are still searching for the abstraction that makes everything click. That moment right before a messy collection of ideas becomes a framework is intellectually chaotic in the best way. It is also where a lot of the interesting questions live.
So that is where blog number two leaves me: somewhere between Transformer scaling laws, utility-grid anxiety, quantum error correction, and the vague feeling that the future of computing is going to be decided by people who understand both software and the physical limits underneath it.
If Transformers became the architecture of attention,
what becomes the architecture of entanglement?
References
- Ashish Vaswani et al., "Attention Is All You Need."
- Jacob Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding."
- Tom B. Brown et al., "Language Models are Few-Shot Learners."
- Alexey Dosovitskiy et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale."
- Duncan McElfresh et al., "When Do Neural Nets Outperform Boosted Trees on Tabular Data?"
- Prafulla Dhariwal and Alexander Nichol, "Diffusion Models Beat GANs on Image Synthesis."
- Albert Gu and Tri Dao, "Mamba: Linear-Time Sequence Modeling with Selective State Spaces."
- International Energy Agency, "Energy and AI: Energy demand from AI."
- Lennart Heim et al., "Managing the Growing Electricity Demand of AI."
- National Academies of Sciences, Engineering, and Medicine, Quantum Computing: Progress and Prospects.
- John Preskill, "Quantum Computing in the NISQ era and beyond."
- Huatang Tan et al., "Artificial intelligence for quantum computing."
- Rajeev Acharya et al., "Quantum error correction below the surface code threshold."
Next issue
More personal, more technical, probably still slightly unhinged.
If you want the next post without visiting this web page each time, subscribe and I'll send it directly.
Subscribe to Newsletter